浏览135次
时间:2019年3月20日 15:01
【摘要】由于现有检索系统的查准率差强人意,我们希望能够挖掘到更多有用的用户数据,以更好地满足用户需求。对于文献检索系统,一个作者所处领域往往与其以往发表论文相关,作者的合作者,发表所在期刊,会议部分程度上也反映了该作者的兴趣取向;与此同时,一个领域专家查询文献时往往希望返回的结果与自己以前的工作内容相关,比如搜索本体时,计算机领域的研究者当然希望返回本体模型,本体匹配,本体相似度等一系列的文献,而哲学领域的研究者也许需要的则是康德的本体论,这样来看,如果我们挖掘到用户的兴趣则能返回更加相关的结果。
【关键词】检索系统;用户数据;本体模型
1. 定义
直观上,用户有关某一个主题发表的文章数越多,则对该主题越感兴趣,这样累加兴趣出现的次数,则可得到用户在某个主题上的累加兴趣值,某种程度上,该值可反映用户的兴趣,对此我们采用文献[8] 中的定义。
定义:用户的累加兴趣值为兴趣在不同年份(因为文献系统中大多情况只列出发表年份)出现次数的总和:
对于主题 x,T 为有关主题 x 文章的发表年份的集合,d(t)为在 t 年发表了该主题多少篇文章。
然而事实并不一定如此,比如 70 年代的著名计算机科学家们都致力于研究编译 x 系统,发表了若干篇有关编译的文章,但之后则对Web 产生的兴趣,但发表的文章数却不多,显然现在他搜索文献时更希望得到有关Web 的文章,也就是说1970 年的兴趣与2010 年的兴趣应当有着不同的贡献值。
考虑到人们对于兴趣的遗忘机制与认知记忆中的遗忘机制非常类似,我们假设人们对某个主题失去兴趣看作是对该兴趣的主动遗忘,将其和Ebbinghaus 曲线结合,利用该曲线描述兴趣。Ebbinghaus 曲线可以通过指数函数进行描述,其中P 表示对保留兴趣值(既用户当年还对某主题有多少兴趣),A 和b 是该函数的两个参数,T 当年时间到文章发表时间的时差。而 Wickelgren[10] 指出,记忆遗忘曲线更符合幂函数,于是我们如下定义:
定义:若以指数函数计算保留兴趣值,可表示为:
若以幂函数计算保留兴趣值,可表示为:
对于主题 x,T 为有关 x 文章的发表年份的集合,d(t) 为在 t 年发表了多少篇有关 x
主题的文章,y0 为当年年份,实际系统中,因为2009 年文献已经收录齐,所以y0 等于2010。
由此可见,研究兴趣x 的保留兴趣值不但取决于兴趣出现频率,还取决于出现后至今的时间长度按。出现频率越高,时延越短,则保留兴趣值越大,反之则越小。ERI 与PRI 公式中参数b 控制曲线衰减速度,而参数A 控制兴趣值的相对大小。
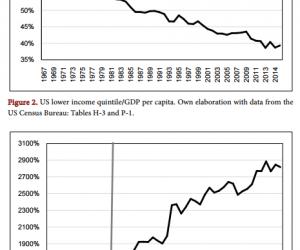
下面两张图是 SelroosO 教授的 9 个发表文章中关键字出现频率最高的兴趣,图 2.1
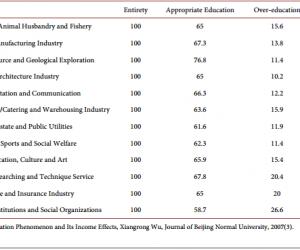
表示累加兴趣值,可见有关 Humans 兴趣的文章发表数量极高,达到了 105,随后我们会讲到这种兴趣太过宽泛,不能代表教授兴趣含义。图2.2 表示幂函数计算出的兴趣值,我们可以发现 SarC 兴趣在累积兴趣时非常高,达到了 45,而在幂函数兴趣值当中却是最低的,这是因为SarC 兴趣大多都在15 年前发表的,对现在兴趣的贡献极小,也就是说SelroosO 教授早已对SarC 不那么感兴趣了,由此可见,幂函数兴趣值更加合理一些,该图所对应的数值可见表2.1:
2. 参数拟合
对于参数 A 和 b 的拟合,我们采取了不同的办法。由于 PRI 与ERI 计算出的保留兴趣值可以看作是对下一年兴趣的预测,这样也就可以得到兴趣的排序,我们每 10 年进行一次预测,将预测的兴趣排序与第11 年的真实排序(第11 年发表的关于该话题的文章数)进行比较,由此来确定b 的参数。
在预测排序与真实排序的相关性计算中,由于在排序中保留兴趣值或者真实的出现次数可能相同,也就有并列排序的情况出现,因此采用Spearman [11] 相关性分析:
其中n 表示一共有多少个序列,xi 和yi 为每个序列中的第i 个取值。预测值与真实值首先需要转化为排序值,在排序中处于同一次序的项被赋予同样的平均值。
实际中,我们不断改变 b 的取值,令 r 趋近于 1,最后得到 b 的取值,需要注意的是b 的拟合与A 无关,因为A 只是一个整体的增量。
对于参数A,它的意义在于它保证保留兴趣值应该与次年实际发表的文章数尽量相同,于是很明显,我们应当用方差比较,拟合参数A,在这里 X 与 Y 是相等的,具体方法见公式3
此外我们还考虑了t 双边检测,这时A 和b 两个参数均对t-test有影响,t-test 公式可见公式2.6:
我们不断改变A 的取值,令θ 趋近于0,最后得到A 的取值,t-test 只是为了检验而用,拟合 A,b 的主要测度还是看 r 和θ,需要注意的是 r 趋近于 1,θ 趋近于 0 并不一定说明它们是最优的,还要进行进一步评估。
3. 兴趣模型评估
参数拟合往往只是数学意义上的模型优化,实际中我们需要将预测值与真实值做比较。直观上,我们应取Medline 中发表文献最多的人,但实际中这些人发表了上千篇文献,而大多是中国人,对此我们猜测是由于 Medline 数据集对人名没有设置独立的 URI 导致的,所以我们选取了发表文章数在300 篇左右的112 位作者(其中去除了中国作者,因为中国姓名重名现象严重),由于他们发表文章比较多,也比较合适,兴趣取向明显,可以更好地拟合模型参数。我们采用PRI公式计算出这些作者2001 至2008 年间的预测兴趣值排序为前9 个的兴趣,将其与真实情况下发表的文章排序做比较。
首先,我们将这112 名作者随机分为2 组,记为 112-1,112-2;对这两组作者的数据进行参数拟合,结果如下,其中112 整体表示为对这112 名作者整体的拟合,其中rho 为公式
结束语:
综上所述,由于一个作者与其合作者的合作情况也可能与时间有关,我们是否可以把合作者直接当作兴趣,直接照搬兴趣模型,计算哪个合作者对这个作者的贡献值高,这样可以帮助用户搜索出更相关的文章或作者。但是兴趣模型能否直接用于合作者,我们还有待考证,毕竟人与人之间的合作关系远比一个人对兴趣的关系复杂得多,是否有更合适的认知模型,或博弈论模型可以加到这里面来,我们需要进一步研究。
参考文献:
[1] 安东尼奥,海尔梅莱恩,陈小平译,语义网基础教程,机械工业出版社,2008
[2] 张玉连,李彦威,王权,原福永,搜索引擎查询日志的聚类。
计算机工程,35(1):43 - 45,2009
[3] 肖卓程,荆金华,基于用户兴趣的搜索引擎. 计算机应用与软件,2007.24(9):134 - 136
[4].Leung KWT, Ng W, Lee DL. Personalized Concept-BasedClustering of Search Engine